
2019年6月,華爲發(fā)布全新8系列手機SoC芯片麒麟810,首次采用華爲自研達芬奇架構NPU,實現業界領先端側AI算力,在業界公認的蘇黎世聯邦理工學(xué)院推出的AI Benchmark榜單中,搭載麒麟810的手機霸榜TOP3,堪稱華爲AI芯片的“秘密武器”,這(zhè)其中華爲自研的達芬奇架構舉足輕重。
那麼(me),達芬奇架構AI實力究竟怎麼(me)樣?一起(qǐ)來深入了解下。
源起(qǐ):爲什麼(me)要做達芬奇架構?
華爲預測,到2025年全球的智能(néng)終端數量將(jiāng)會達到400億台,智能(néng)助理的普及率將(jiāng)達到90%,企業數據的使用率將(jiāng)達到86%。可以預見,在不久的將(jiāng)來,AI將(jiāng)作爲一項通用技術極大地提高生産力,改變每個組織和每個行業。
基于這(zhè)樣的願景,華爲在2018全聯接大會上提出全棧全場景AI戰略。作爲重要的技術基礎,AI芯片在其中發(fā)揮着重要作用,而華爲也基于AI芯片提供了完整的解決方案,加速使能(néng)AI産業化。
爲了實現AI在多平台多場景之間的協同,華爲創新設計達芬奇計算架構,在不同體積和功耗條件下提供強勁的AI算力。
初見:達芬奇架構的核心優勢
達芬奇架構,是華爲自研的面(miàn)向(xiàng)AI計算特征的全新計算架構,具備高算力、高能(néng)效、靈活可裁剪的特性,是實現萬物智能(néng)的重要基礎。
具體來說,達芬奇架構采用3D Cube針對(duì)矩陣運算做加速,大幅提升單位功耗下的AI算力,每個AI Core可以在一個時鍾周期内實現4096個MAC操作,相比傳統的CPU和GPU實現數量級的提升。
同時,爲了提升AI計算的完備性和不同場景的計算效率,達芬奇架構還(hái)集成(chéng)了向(xiàng)量、标量、硬件加速器等多種(zhǒng)計算單元。同時支持多種(zhǒng)精度計算,支撐訓練和推理兩(liǎng)種(zhǒng)場景的數據精度要求,實現AI的全場景需求覆蓋。
深耕:達芬奇架構的AI硬實力
科普1:常見的AI運算類型有哪些?
在了解達芬奇架構的技術之前,我們先來弄清楚一下幾種(zhǒng)AI運算數據對(duì)象:
· 标量(Scalar):由單獨一個數組成(chéng)
· 向(xiàng)量(Vector):由一組一維有序數組成(chéng),每個數由一個索引(index)标識
· 矩陣(Matrix):由一組二維有序數組成(chéng),每個數由兩(liǎng)個索引(index)标識
· 張量(Tensor):由一組n維有序數組成(chéng),每個數由n個索引(index)标識
其中,AI計算的核心是矩陣乘法運算,計算時由左矩陣的一行和右矩陣的一列相乘,每個元素相乘之後(hòu)的和輸出到結果矩陣。
在此計算過(guò)程中,标量(Scalar)、向(xiàng)量(Vector)、矩陣(Matrix)算力密度依次增加,對(duì)硬件的AI運算能(néng)力不斷提出更高要求。
典型的神經(jīng)網絡模型計算量都(dōu)非常大,這(zhè)其中99%的計算都(dōu)需要用到矩陣乘,也就是說,如果提高矩陣乘的運算效率,就能(néng)最大程度上提升AI算力——這(zhè)也是達芬奇架構設計的核心:以最小的計算代價增加矩陣乘的算力,實現更高的AI能(néng)效。
科普2:各單元角色分工揭秘,Da Vinci Core是如何實現高效AI計算的?
在2018年全聯接大會上,華爲推出AI芯片Ascend 310(昇騰310),這(zhè)是達芬奇架構的首次亮相。

其中,Da Vinci Core隻是NPU的一個部分,Da Vinci Core内部還(hái)細分成(chéng)很多單元,包括核心的3D Cube、Vector向(xiàng)量計算單元、Scalar标量計算單元等,它們各自負責不同的運算任務實現并行化計算模型,共同保障AI計算的高效處理。
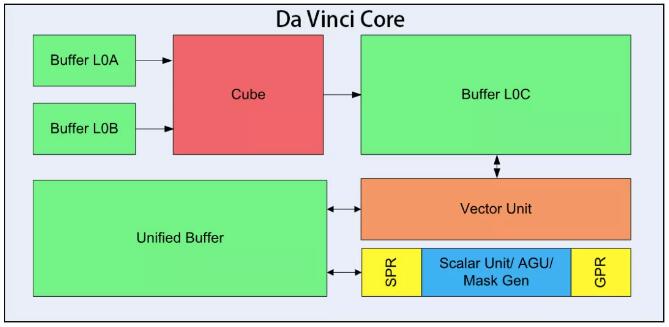
· 3D Cube矩陣乘法單元:算力擔當
剛才已經(jīng)提到,矩陣乘是AI計算的核心,這(zhè)部分運算由3D Cube完成(chéng),Buffer L0A、L0B、L0C則用于存儲輸入矩陣和輸出矩陣數據,負責向(xiàng)Cube計算單元輸送數據和存放計算結果。
· Vector向(xiàng)量計算單元:靈活的多面(miàn)手
雖然Cube的算力很強大,但隻能(néng)完成(chéng)矩陣乘運算,還(hái)有很多計算類型要依靠Vector向(xiàng)量計算單元來完成(chéng)。Vector的指令相對(duì)來說非常豐富,可以覆蓋各種(zhǒng)基本的計算類型和許多定制的計算類型。
· Scalar标量計算單元:流程控制的管家
Scalar标量運算單元主要負責AI Core的标量運算,功能(néng)上可以看作一個小CPU,完成(chéng)整個程序的循環控制,分支判斷,Cube、Vector等指令的地址和參數計算以及基本的算術運算等。
科普3:3D Cube計算方式的獨特優勢是什麼(me)?
不同于以往的标量、矢量運算模式,華爲達芬奇架構以高性能(néng)3D Cube計算引擎爲基礎,針對(duì)矩陣運算進(jìn)行加速,大幅提高單位面(miàn)積下的AI算力,充分激發(fā)端側AI的運算潛能(néng)。
以兩(liǎng)個N*N的矩陣A*B乘法爲例:如果是N個1D 的MAC,需要N^2(即N的2次方)的cycle數;如果是1個N^2的2D MAC陣列,需要N個Cycle;如果是1個N維3D的Cube,隻需要1個Cycle。

圖中計算單元的數量隻是示意,實際可靈活設計
華爲創新設計的達芬奇架構將(jiāng)大幅提升算力,16*16*16的3D Cube能(néng)夠顯著提升數據利用率,縮短運算周期,實現更快更強的AI運算。
這(zhè)是什麼(me)意思呢?舉例來說,同樣是完成(chéng)4096次運算,2D結構需要64行*64列才能(néng)計算,3D Cube隻需要16*16*16的結構就能(néng)算出。其中,64*64結構帶來的問題是:運算周期長(cháng)、時延高、利用率低。
達芬奇架構的這(zhè)一特性也完美體現在麒麟810上。作爲首款采用達芬奇架構NPU的手機SoC芯片,麒麟810實現強勁的AI算力,在單位面(miàn)積上實現最佳能(néng)效,FP16精度和INT8量化精度業界領先,搭載這(zhè)款SoC芯片的華爲Nova 5、Nova 5i Pro及榮耀9X手機已上市,爲廣大消費者提供多種(zhǒng)精彩的AI應用體驗。
同時,麒麟810再度賦能(néng)HiAI生态,支持自研中間算子格式IR開(kāi)放,算子數量多達240+,處于業内領先水平。更多算子、開(kāi)源框架的支持以及提供更加完備的工具鏈將(jiāng)助力開(kāi)發(fā)者快速轉換集成(chéng)基于不同AI框架開(kāi)發(fā)出的模型,極大地增強了華爲HiAI移動計算平台的兼容性、易用性,提高開(kāi)發(fā)者的效率,節約時間成(chéng)本,加速更多AI應用的落地。

預見:達芬奇架構解鎖AI無限可能(néng)
基于靈活可擴展的特性,達芬奇架構能(néng)夠滿足端側、邊緣側及雲端的應用場景,可用于小到幾十毫瓦,大到幾百瓦的訓練場景,橫跨全場景提供最優算力。
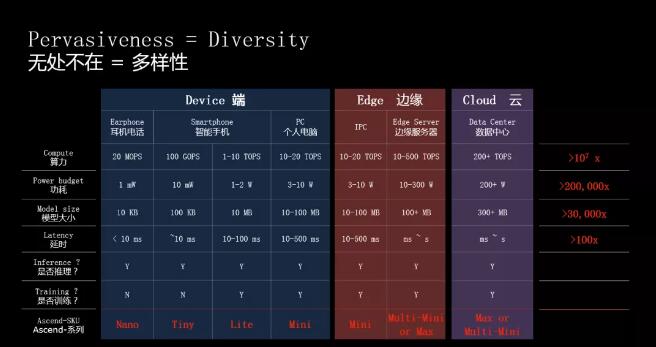
以Ascend芯片爲例,Ascend-Nano可以用于耳機電話等IoT設備的使用場景;Ascend-Tiny和Ascend-Lite用于智能(néng)手機的AI運算處理;在筆記本電腦等算力需求更高的便攜設備上,由Ascend-Mini提供算力支持;而邊緣側服務器上則需要由Multi-Ascend 310完成(chéng)AI計算;至于超複雜的雲端數據運算處理,則交由算力最高可達256 TFLOPS@FP16的Ascend-Max來完成(chéng)。
正是由于達芬奇架構靈活可裁剪、高能(néng)效的特性,才能(néng)實現對(duì)上述多種(zhǒng)複雜場景的AI運算處理。
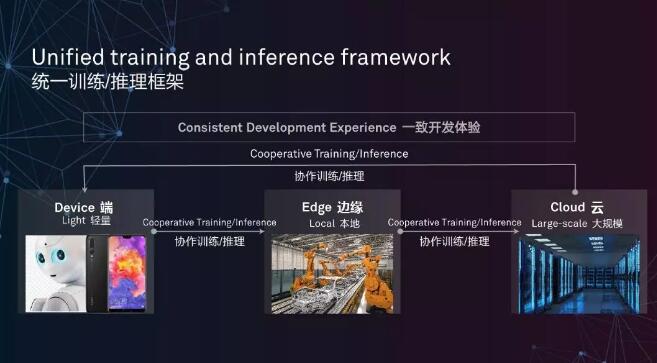
同時,選擇開(kāi)發(fā)統一架構也是一個非常關鍵的決策。統一架構優勢很明顯,那就是對(duì)廣大開(kāi)發(fā)者非常利好(hǎo)。基于達芬奇架構的統一性,開(kāi)發(fā)者在面(miàn)對(duì)雲端、邊緣側、端側等全場景應用開(kāi)發(fā)時,隻需要進(jìn)行一次算子開(kāi)發(fā)和調試,就可以應用于不同平台,大幅降低了遷移成(chéng)本。
不僅開(kāi)發(fā)平台語言統一,訓練和推理框架也是統一的,開(kāi)發(fā)者可以將(jiāng)大量訓練模型放在本地和雲端服務器,再將(jiāng)輕量級的推理工作放在移動端設備上,獲得一緻的開(kāi)發(fā)體驗。
在算力和技術得到突破性提升後(hòu),AI將(jiāng)廣泛應用于智慧城市、自動駕駛、智慧新零售、機器人、工業制造、雲計算AI服務等場景。華爲輪值董事(shì)長(cháng)徐直軍在2018華爲全聯接大會上表示,“全場景意味着可以實現智能(néng)無所不及,全棧意味着華爲有能(néng)力爲AI應用開(kāi)發(fā)者提供強大的算力和應用開(kāi)發(fā)平台;有能(néng)力提供大家用得起(qǐ)、用得好(hǎo)、用得放心的AI,實現普惠AI”。
未來,AI將(jiāng)應用更加廣泛的領域,并逐漸覆蓋至生活的方方面(miàn)面(miàn)。達芬奇架構作爲AI運算的重要技術基礎,將(jiāng)持續賦能(néng)AI應用探索,爲各行各業的AI應用場景提供澎湃算力。
8月23日,采用達芬奇架構的又一款“巨無霸”——AI芯片Ascend 910,將(jiāng)正式商用發(fā)布,與之配套的新一代AI開(kāi)源計算框架MindSpore也將(jiāng)同時亮相。